 CATS LAB
CATS LAB认识GPU
1 GPU简单介绍
GPU(Graphics Processing Unit)也叫做图形处理单元,是一种专用电子电路,最初设计使用来加速计算机图形处理,但后续因其并行结构非常适合与并行计算领域。GPU一共经历了三个历史发展阶段。下面是显卡示意图,主要由GPU和显存组成。
1.1 GPU的发展阶段
1.1.1 硬件加速阶段
在1999年以前,将CPU的部分功能剥离出来,形成单独的硬件,实现对图像的硬件加速,只起到3D图像处理的加速作用,不具备软件编程特征。
1.1.2有限编程阶段
1999-2005年,进一步的硬件加速,但是出现了有限编程性。
1999年,Nvidia发布了专为执行复杂的数学和几何计算的GeForce256图像处理芯片,不同于CPU将晶体管主要用作控制单元和缓存,更多的作为执行单元,将图形变换以及照明等功能从CPU剥离出来,通过变换引擎和照明引擎实现了图形的快速变换以及光照计算,成为GPU出现的标志。
2000-2005,GPU技术快速发展,运算速度迅速超过GPU。Nvidia和ATI(被AMD收购)分别推出的GeForce3和Radeon 8500 ,出现顶点可编程性和像素级可编程性,但是总体上编程性十分有限。
1.1.3 软件可编程阶段
2006年,Nvidia和ATI分别推出了CUDA(Compute United Device Architecture)和CTM(Close To Metal)编程环境,使得GPU打破图形语言的局限成为真正的额并行数据处理超级加速器。
2008年,苹果提出通用的并行计算编程平台OpenCL,与具体平台无关,迅速成为移动端GPU的编程环境业界标准。
1.2 GPU工作原理
1.2.1基本概念解释
GPU的设计目标是最大化吞吐量(Throughout)和并行度(Parallelism)。而CPU更关心延迟(Latency)和并发(concurrency)。于是GPU采用了SIMT架构,单核CPU通常采用SIMD架构,多核CPU则通常采用MIMD架构。
CPU旨在以尽可能快的速度执行线程,并且可以并行执行几十个这些线程。而GPU试图通过并行执行数千个线程从而分摊时延以实现更高的吞吐量。 GPU专门用于高度并行计算,因此设计时更多的晶体管用于数据处理而不是数据缓存和流程控制。

延迟: 完成单项任务所消耗的时间。
并行: 同时处理多个任务,任务之间存在干扰。
并发: 一段时间内处理多个任务,任务之间可能互相干扰。
SIMD: SIMD(单指令多数据流)是从SISD(单指令单数据流)发展出来的。想要执行并行需要通过堆叠多个核心从而实现并行,每个核心执行一个线程,即MIMD(多指令多数据流)。而SIMD的想法是通过给每个核心中增加计算单元和寄存器,减少硬件开销。然后增加指令的操作数个数,使得一条指令可以驱动多个计算元件同时执行多个数据运算。
SIMT: SIMD看起来很好,但是对于高级语言的支持并不好。SIMT(单指令多线程)从本质上还是一套控制单元带多个计算单元,但是从一条指令控制多个计算单元和寄存器,变为将一条指令分发给多组计算单元和寄存器,从而优化高级语言的支持。
1.2.2 缓存机制
CPU中的缓存是为了存储下一步要计算的数据,从而减少访问数据的时延,提高线程的执行速度,从而实现高并发。而在GPU中缓存是为Thread提供服务的,缓存会合并线程相同的数据访问,让后从DRAM中访问数据,分发给线程。

HBM: 高带宽内存,也就是显存。它通过将内存芯片直接堆叠在逻辑芯片上,提供了极高的带宽和更低的能耗,从而实现了高密度和高带宽的数据传输。
L1 Cache/SMEM:L1 Cache包含指令缓存(Instruction Cache)和数据缓存(Data Cache),在SM内部存储最常用的指令和数据,每个SM独享一个L1 Cache,提供低延迟和高带宽的访问。
Register File: 用于存储临时数据、计算中间结果和变量。离计算单元最近,访问速度非常快。
带宽(BandWidth): 单位时间内传输的数据量,主要有内存频率(Memory Data Rate)以及位宽(Memory Interface)决定的。例如A100的位宽是5210bit,频率是1215MHz,所以带宽为$\frac{(\frac{5210}{8}\times1215\times10^6\times2)}{10^{9}}=1555GB/s$,乘2是因为DDR技术每个时钟周期传输两次数据,计算存储和传输时进制是$10^3$。
计算强度: 计算时间/内存读取时间。存储带宽越小计算强度应该越高,从而提高效率。
1.2.3 线程机制:
Warp: 线程束。逻辑上,所有Thread是并行;但是,从硬件的角度来说,并不是所有的 Thread能够在同一时刻执行,这里就需要Warp的引入。
Warp 是 SM 基本执行单元,一个 Warp 包含32个并行 Thread,这32个 Thread 执行于 SIMT模式。也就是说所有 Thread 以锁步的方式执行同一条指令,但每个 Thread 会使用各自的 Data 执行指令分支。如果在 Warp 中没有32个 Thread 需要工作,那么 Warp 虽然还是作为一个整体运行,但这部分 Thread 是处于非激活状态的
2 Nvidia GPU 介绍
2.1 基础概念
2.1.1 CUDA线程层次结构
在A100的线程层次中由三层构成,grid(网格)、block(线程块)、thread(线程)。但是在H100中有引入了新的一层Cluster(簇)这里暂且不管。
这里姑且将在GPU上的任务称为kernel,一个kernel所调用的所有线程组成了grid。网格又可以拆分成拥有相同线程数的block。
Grid: 同一个网格上的线程共享相同的全局内存空间。grid是线程结构的第一层次。对应于GPU设备device。
Block: Block 间并行执行,并且无法通信,==没有执行顺序==,每个 block 包含共享内存(Shared Memory),可以里面的 Thread 共享。对应由于SM,A100中一个block包含2048个thread。
Thread: 同一个 block 中 thread 可以同步,也可以通过 Shared memory 通信,对应于cuda core。

2.1.2 CUDA 内存层次结构


寄存器(Register): 寄存器对于每个线程来说都是私有的,一个核函数通常使用寄存器来保存需要频繁访问的线程私有变量。寄存器变量与核函数的生命周期相同。一旦核函数执行完毕,就不能对寄存器变量进行访问了。
局部内存(Local Memory): 局部内存是私有的,只有本线程才能进行读写访问。主要存储超出寄存器存储上线的数据,以及编译器无法静态确定的数据,局部内存在HBM上。
共享内存(Shared Memory): 一个块可以被同一block中的所有线程访问的可读写存储器。访问共享存储器的速度几乎和访问寄存器一样快。是实现线程间通信的延迟最小的方法。
常量内存(Constant Memory): 常量内存(const memory)是只读全局内存,在HBM中,但是其中的数据可以缓存在SM内部的常量缓存中(const cache)只。
纹理内存(Texture Memory): 纹理内存类似于常量缓存,也是一种具有缓存的只读全局内存,与常量内存具有相同的生命周期和作用范围。纹理内存通常比常量内存要大,适合实现图像处理和查找表等操作。
全局内存(Global Memory): 全局内存由于存放在HBM上,是GPU中容量最大、延迟最高的内存,主要作用是给核函数提供数据。GPU内核的所有线程都能对全局内存进行访问,但是访存的开销很大。
2.1.4 计算性能
$F_{clk}$:为 GPU 时钟周期内指令执行数 (FLOPS/Cycle)。
$N_{SM}$:为 GPU SM 数量 (Cores)。
$F_{req}$:为运行频率 (GHz)。
2.2 Nvidia架构

注意同同一架构不同型号的GPU存在差异。
2.2.1 Fermi 费米架构

首先从总体角度进行分析:GPU通过HostInterface,接收来自主机的指令与数据。使用一个Giga Thread Engine来管理所有正在进行的工作。GPU被划分成多个Graphics Processing Cluster(图形处理簇),每个GPC拥有多个SM和一个Raster Engine(光栅化引擎)。它们其中有很多的连接,最显著的是Crossbar,它可以实现GPC之间的通信并来连接其它功能性模块(例如ROP或其他子系统)。
Raster Engine:主要负责将图形管线中的矢量图形数据(如顶点)转换为像素信息(光栅图像)的部分。
ROP(Raster Operations Pipeline):光栅操作单元,负责将光栅化引擎生成的像素数据进行最终处理,并将处理后的像素输出到帧缓冲区中,最终生成可在显示设备上显示的图像。
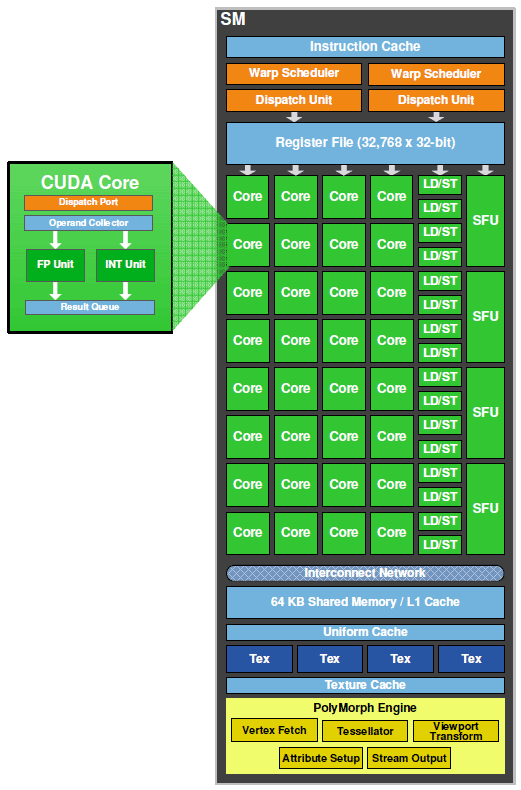
32 个 CUDA Core(分在两条 lane 上,每条分别是 16 个), 每个 CUDA Core 里面是 1 个单精浮点单元(FPU)和 1 个整数单元(ALU)。
- 每个 cycle 可以跑 16 个双精的 FMA
-
SM:从 G80 提出的概念,中文称流式多处理器,核心组件包括CUDA核心、共享内存、寄存器等。SM包含许多为线程执行数学运算的Core,是 NVIDA 的核心。
-
CUDA Core:向量运行单元
- SP(Streaming processor):流式处理器最基本的处理单元,Fermi 架构后,SP被改称为CUDA Core,最后线程具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。一个SP对应一个线程。
- FP32-FPU:单精度浮点数运算单元
- FP64-DPU:双精度浮点数运算单元
- INT32-ALU:整数运算单元
-
Special Function Units:特殊函数单元 SFU,计算超越函数和数学函数,例如余弦函数,但是存在精度损失。
-
Warp Scheduler:线程束调度器,用于将一批批的Warp发送给特定的计算核心SP执行计算。一个Warp由32个线程组成。
-
Dispatch Unit:指令分发单元,Dispatch Units负责将Warp Scheduler的指令送往Core执行(也就是上面的SP)。
-
Load/Store:加载/存储模块。辅助一个Warp(线程组)从Share Memory或显存加载(Load)或存储(Store)数据。这个单元处理操作都是异步的,也就是说其他单元在高速处理指令的时候,如果需要加载或者写回数据,则不会在这里等待LD/ST返回数据,而是跳转执行其他指令,待LD/ST把数据取到或者写回之后,再继续执行需要这些数据的后续指令。
-
Tex Unit:纹理(texture)读取单元,texture指通常理解的1D/2D/3D结构数据,相邻数据之间存在一定关系,或者相邻数据之间需要进行相同的运算。在一个运算周期最多可取4个采样器,这时刚好喂给一个线程束,每个Texture Uint有16K的Texture Cache,并且在往下有L2 Cache的支持。
-
PolyMorph Engine: 负责属性装配(attribute Setup)、顶点拉取(Vertex Fetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)
- Vertex Fetch模块:顶点处理前期的通过三角形索引取出三角形数据。
- Tesselator模块:对应着DX11引入的新特性曲面细分。
- Stream Output模块:对应着DX10引入的新特性Stream Output。
- Viewport Transform模块:对应着顶点的视口变换,三角形会被裁剪准备栅格化。
- Attribute Setup模块:负责顶点的插值运算并输出给后续像素处理阶段使用。
-
Instruction Cache:指令缓存。存放将要执行的指令,通过Dispatch Units填装到每个运算核心(Core)进行运算。
-
Uniform Cache:用于提高对uniform变量访问的效率。Uniform变量是在着色器程序中使用的常量,它们对于一个渲染调用中的所有顶点或片元是相同的。这些变量包括但不限于矩阵(用于变换或投影)、光照参数、或者其他在着色器执行期间不会改变的全局状态信息。后续演化为constant cache。
-
Interconnect Network:是一个关键组件,它负责处理GPU内部各个部分之间的数据传输和通信。这个网络使得多个处理核心(CUDA核心)、内存控制器、缓存系统等可以高效地交换数据,从而提高整体的处理速度和效率。
2.2.2 Kepler 开普勒架构

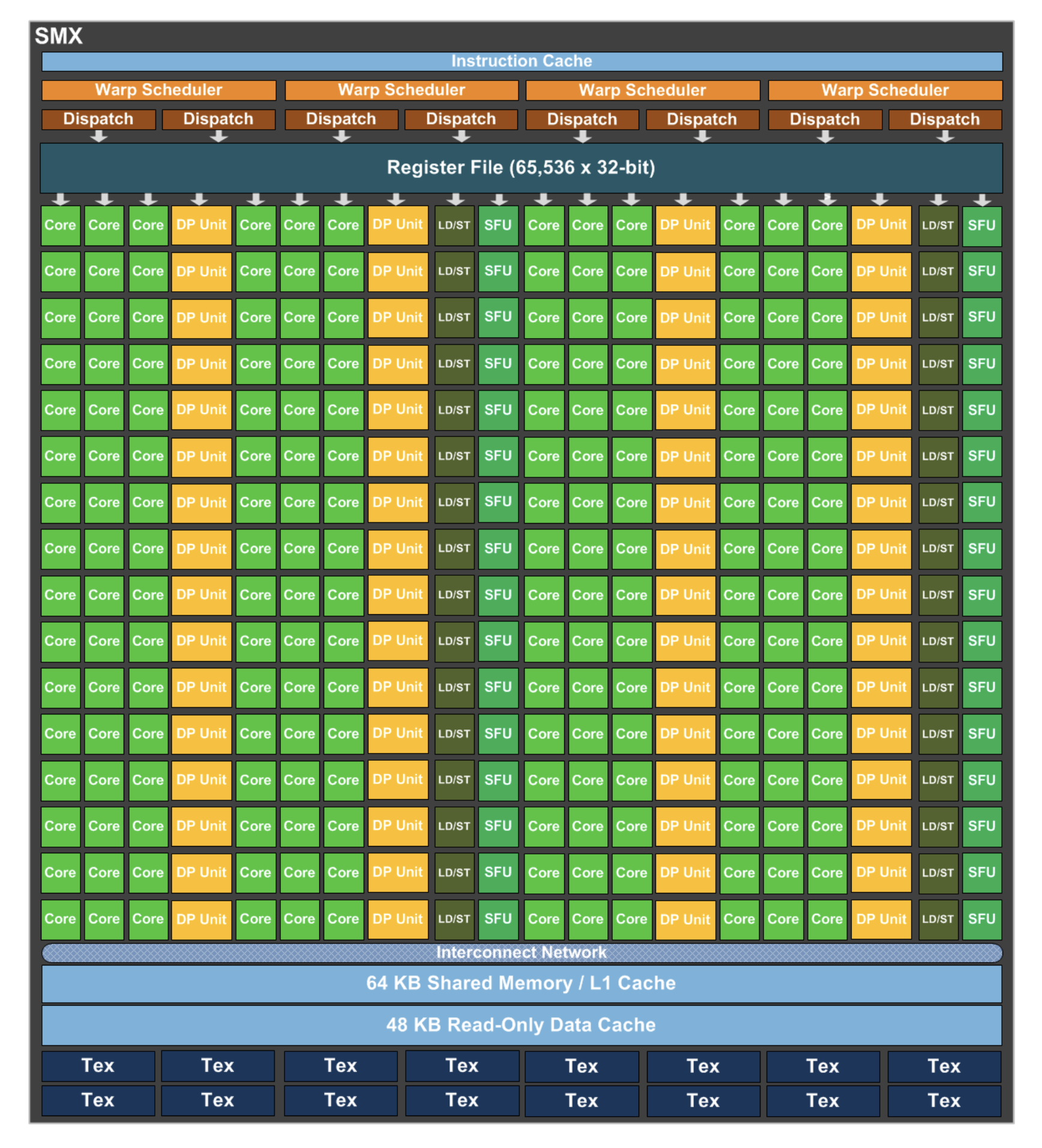
相较于Fermi架构的变化不大。
- SM改名成了SMX,但是所代表的概念没有大变化;
- 单个SMX的Cuda Core数量从32个增加到了192个($4\times3\times16$),很奇怪的数字。
- Kepler架构在硬件上直接有双精运算单元的架构;
- 提出 GPU Direct 技术,可以绕过 CPU/System Memory,完成与本机其他 GPU 或者其他机器 GPU 的直接数据交换。
2.2.3 Maxwell 麦克斯韦架构
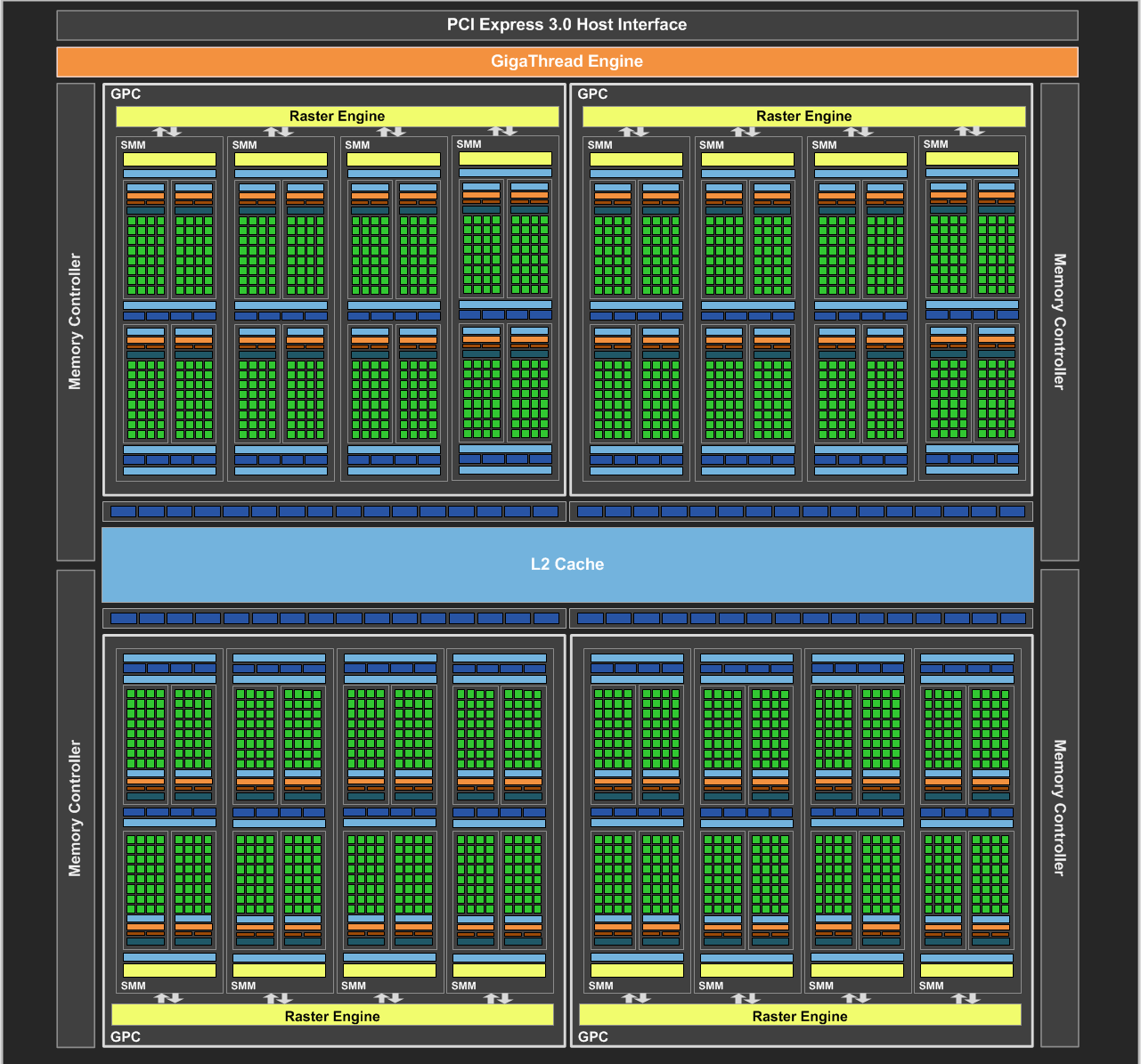

Kepler架构的SMX过于庞杂,因此Maxwwll 的SMM砍掉了很多元件,将类似于Fermi架构的四个SM(Process Block)拼成了一个SMM。
2.2.4 Pascal 帕斯卡架构
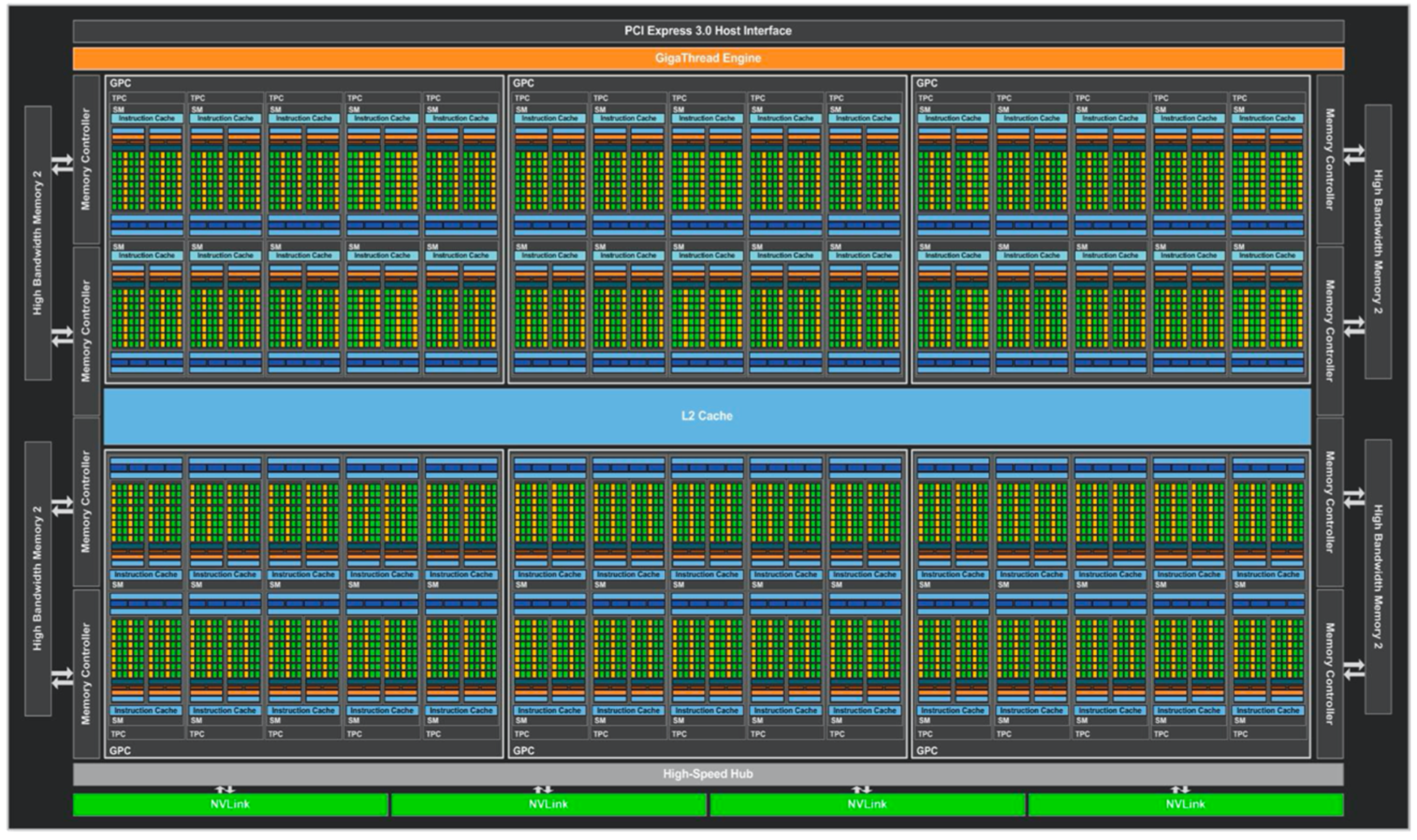

- 单个SM只有64个FP32 CUDA Cores,相比Maxwell的128和Kepler的192,这个数量要少很多,并且64个CUDA Cores分为了两个区块;
- Register File 保持相同大小,每个线程可以使用更多寄存器,单个SM也可以并发更多 thread/warp/block;
- 增加 32个FP64 CUDA Cores (DP Unit),FP32 CUDA Core 具备处理FP16的能力。
- 出现了TPC层次
- 引入了NVLink
2.2.5 Volta 伏特架构
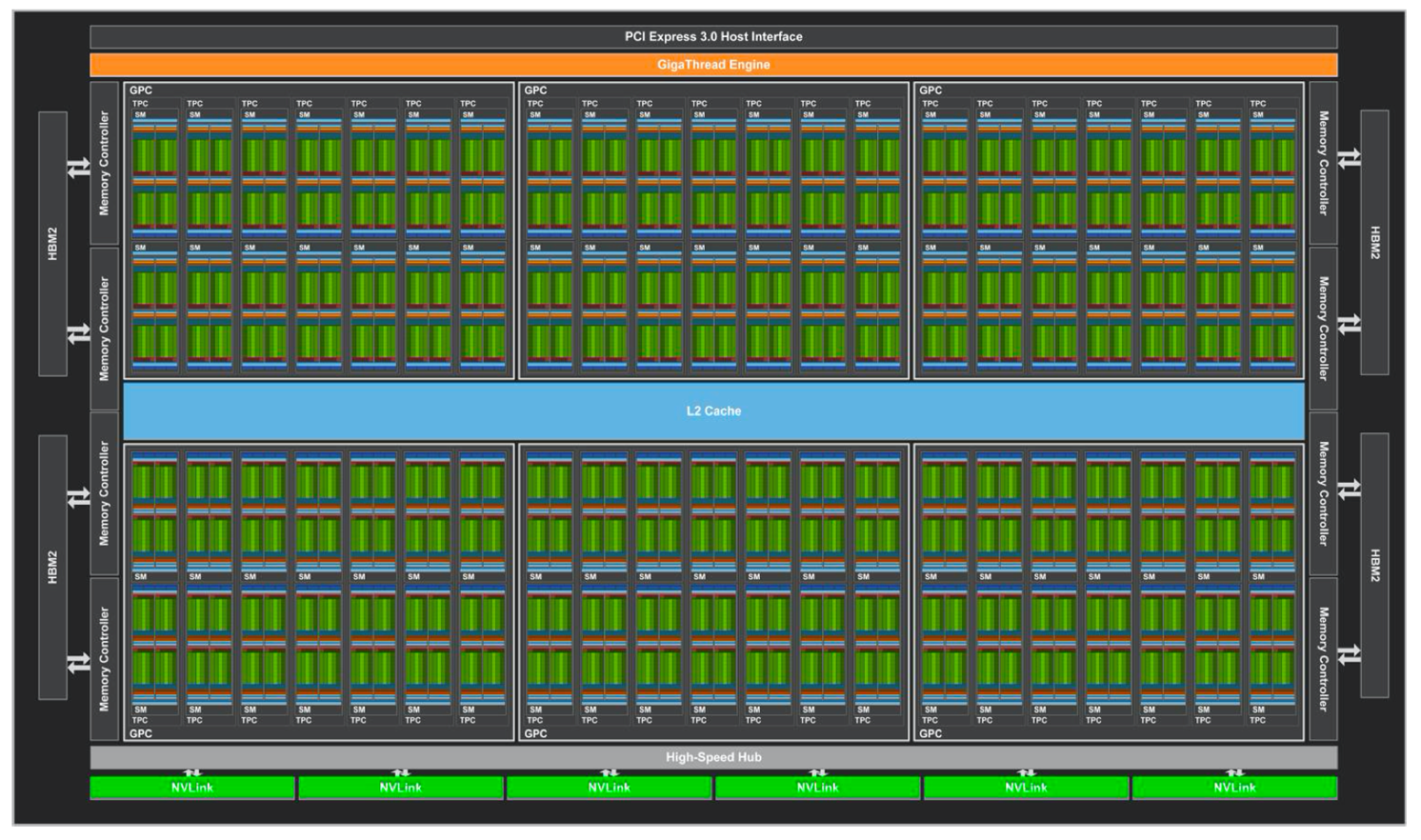
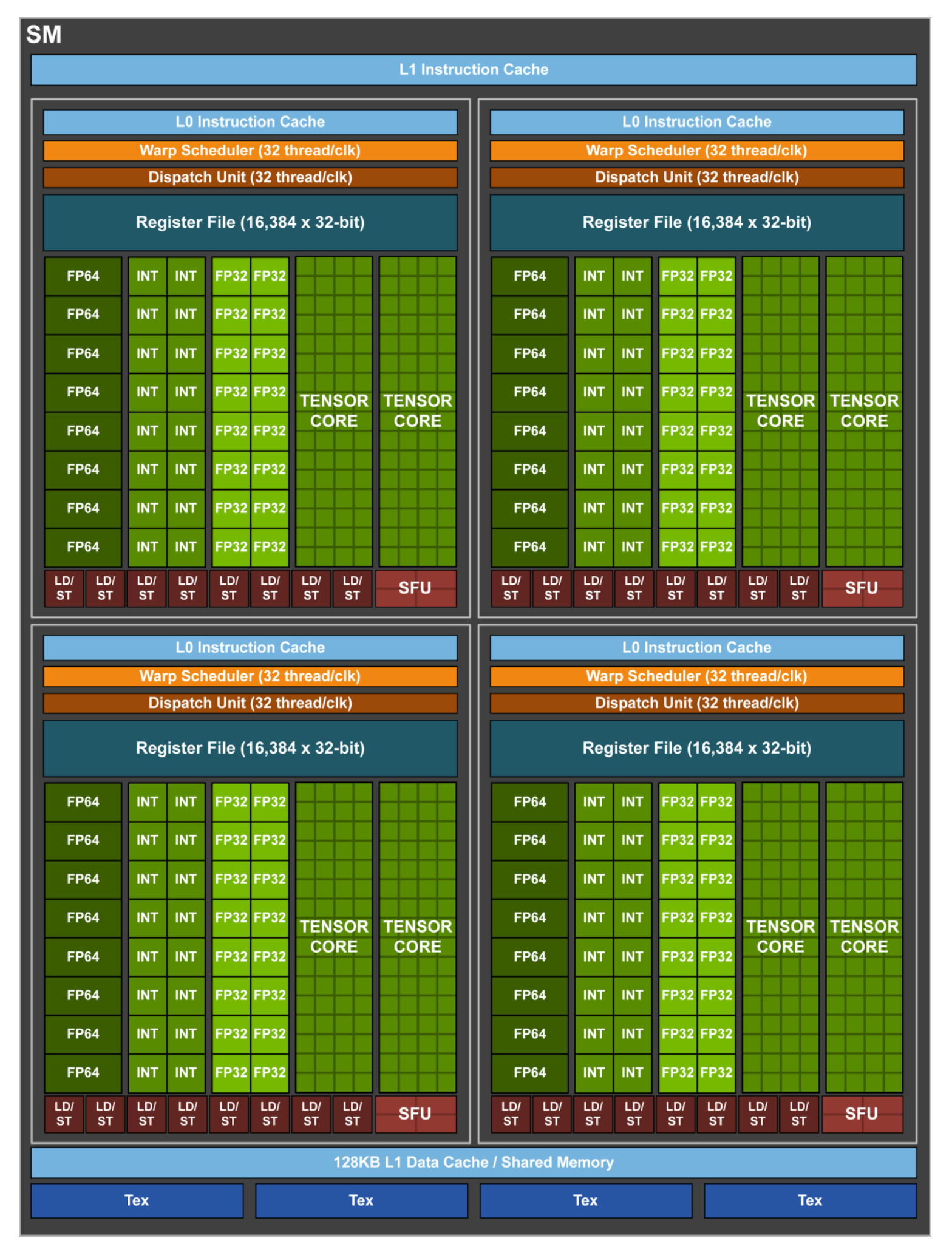
最显著的变化就是cuda core被拆分,整形计算单元和FP32计算单元独立出现在流水线中。可以在一个时钟周期内同时执行整形计算和单精度浮点数运算。同时相对于Pascal每个区块又被一分为二。不难看出在减小每个区块以及每个SM运算单元的数量,同时增加SM的数量。
最重要的是引入了张量核心(Tensor Core)。
2.2.6 Turing 图灵架构
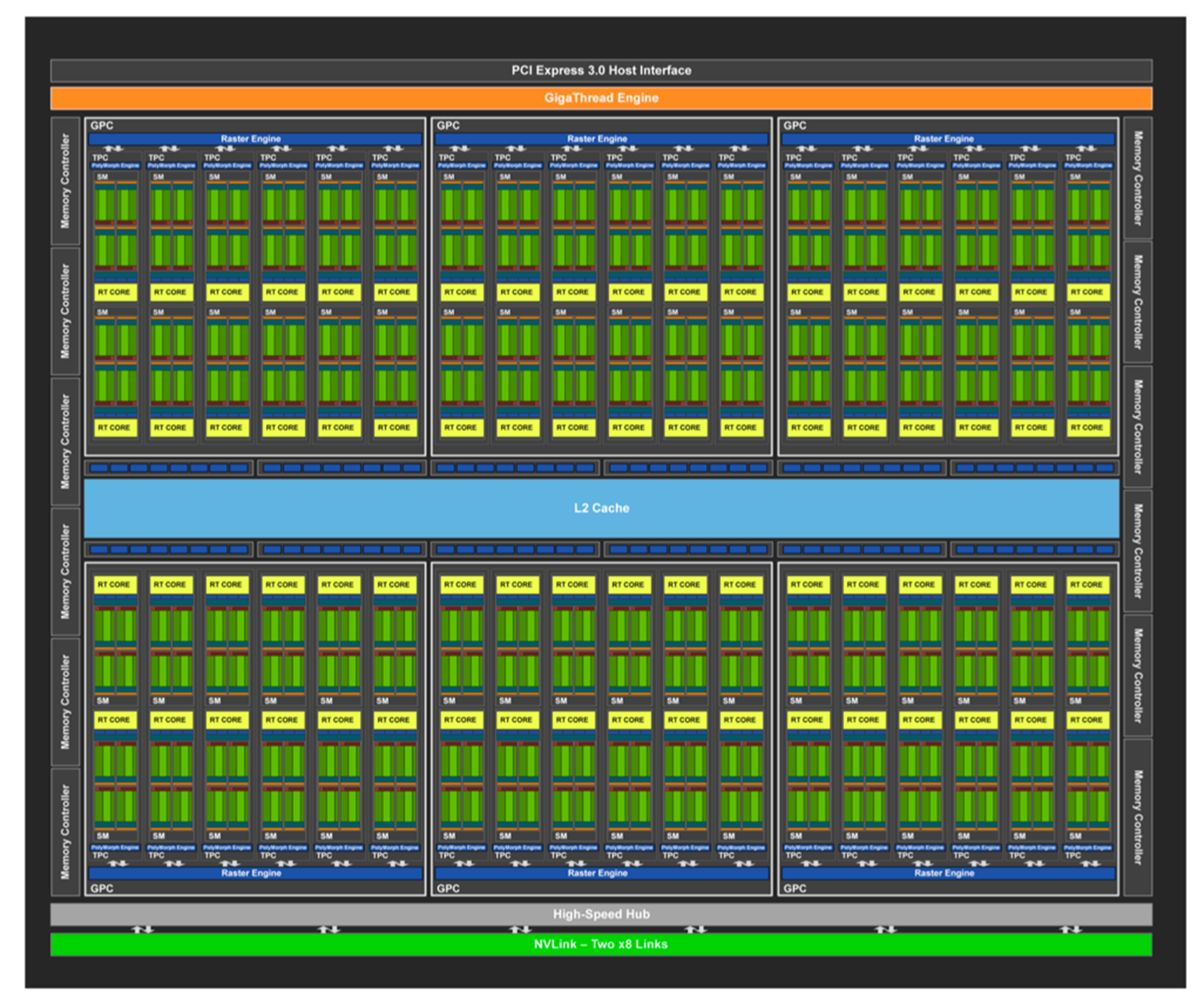
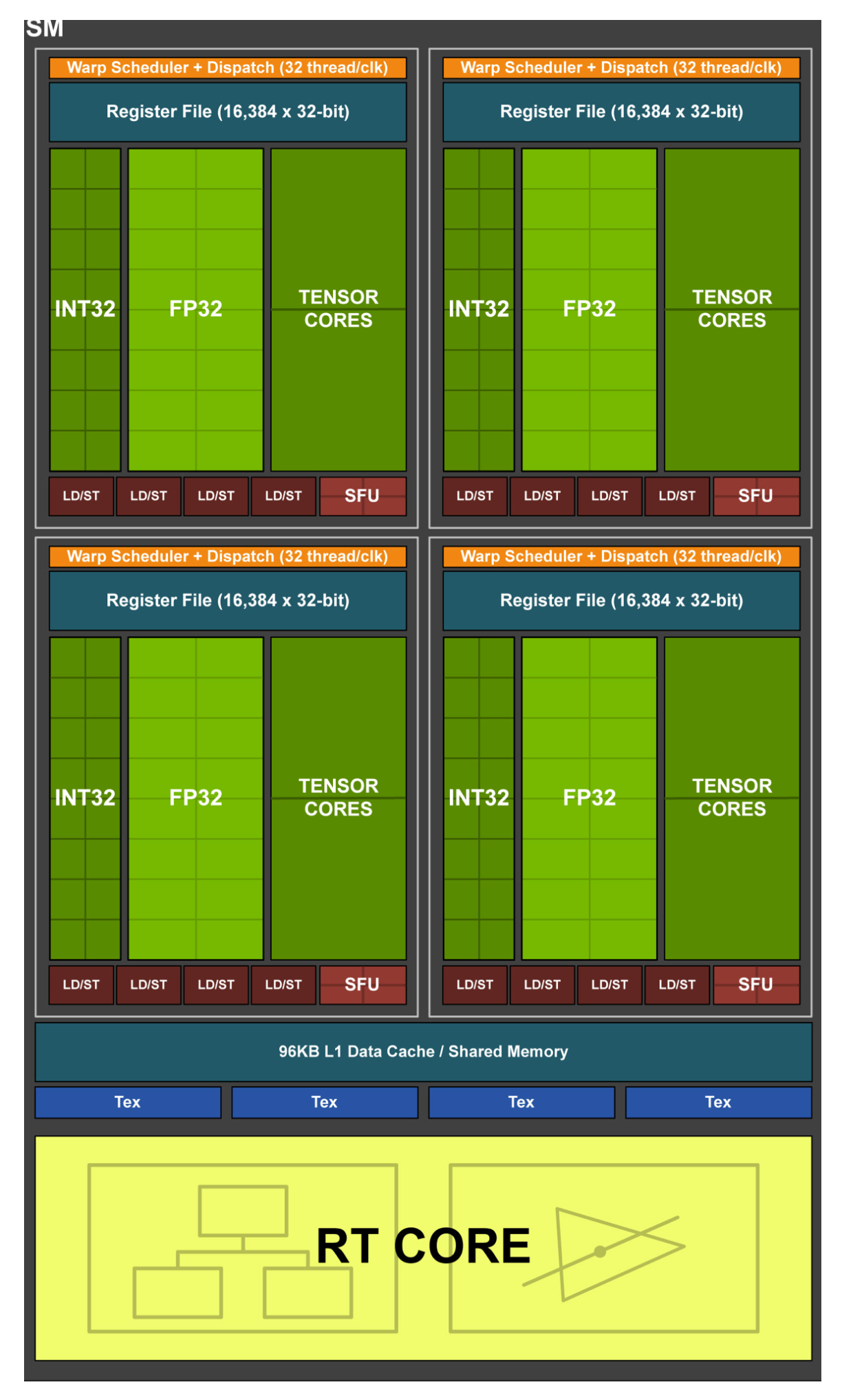
2.2.7 Ampere 安培架构
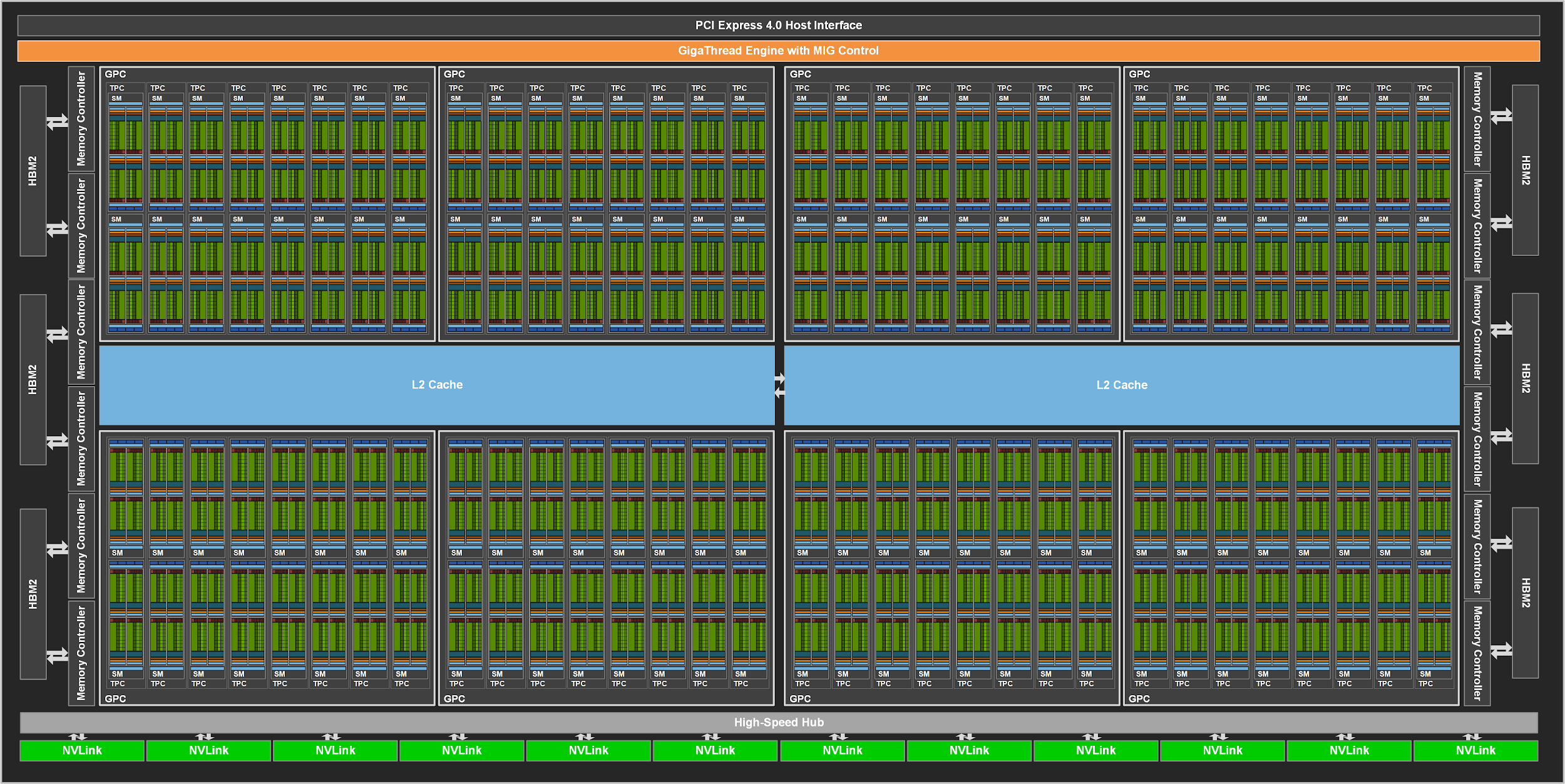
增加了FP64单元,Tensor Core变为原来的一半,但是计算能力其实增强了,单个时钟周期吞吐量量提高了,同时引入了结构化稀疏能力。增加了多实例GPU(Multi-Instance GPU),将单个A100GPU划分为多达七个独立GPU,为不同任务提供不同算力。
引入了TF32 和BF16的支持:

2.2.8 Hopper 赫柏架构
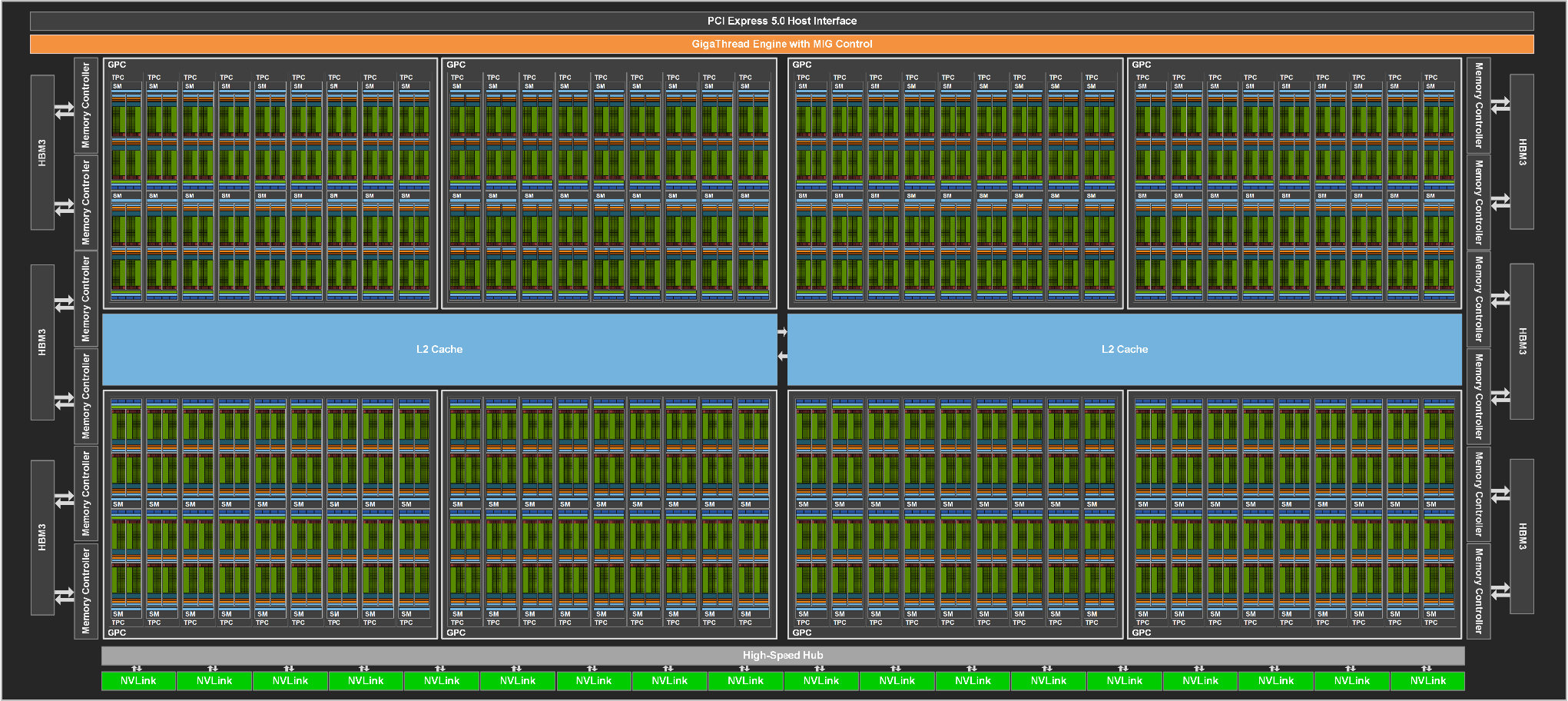
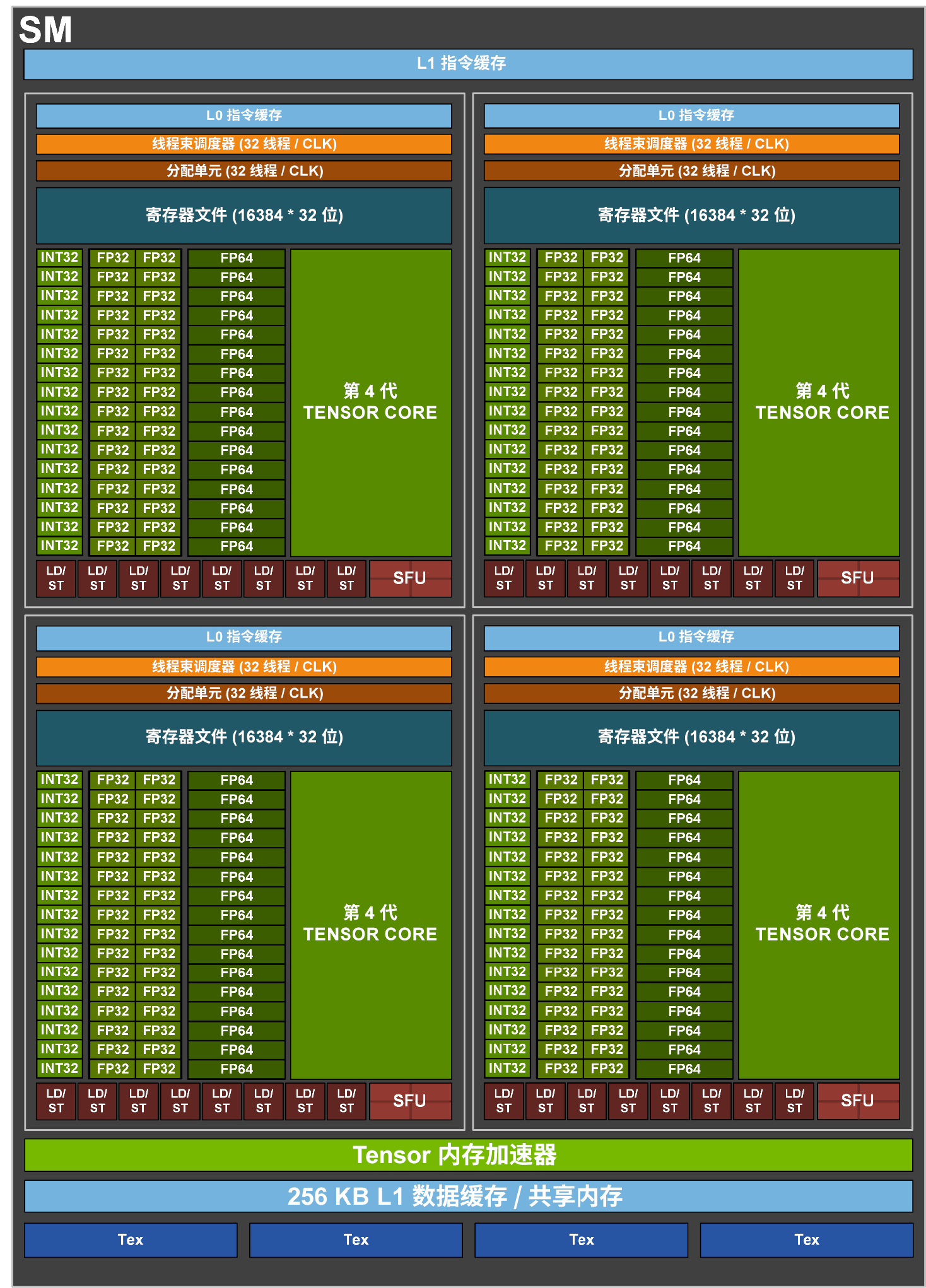
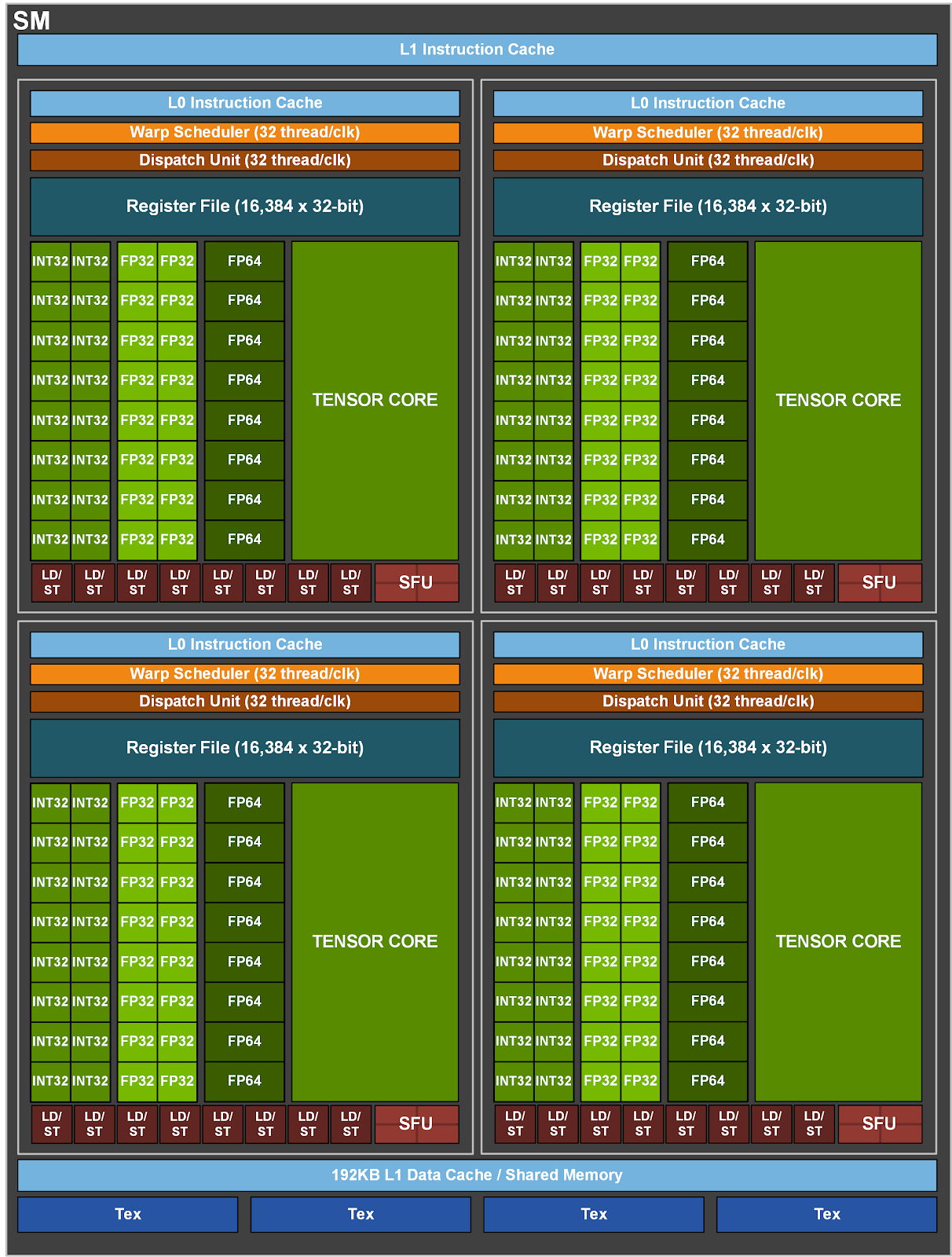
SM 结构:
- 4 个 Warp Scheduler,4 个 Dispatch Unit(与 A100 一致)
- 128 个 FP32 Core(4 * 32)(相比 A100 翻倍)
- 64 个 INT32 Core(4 * 16)(与 A100 一致)
- 64 个 FP64 Core(4 * 16)(相比 A100 翻倍)
- 4 个 TensorCore(4 * 1)
- 32 个 LD/ST Unit(4 * 8)(与 A100 一致)
- 16 个 SFU(4 * 4)(与 A100 一致)
- 相比 A100 增加了一个 Tensor Memory Accelerator
Process Block:
- 1 个 Warp Scheduler,1 个 Dispatch Unit(与 A100 一致)
- 32 个 FP32 Core(相比 A100 翻倍)
- 16 个 INT32 Core(与 A100 一致)
- 16 个 FP64 Core(相比 A100 翻倍)
- 1 个 TensorCore
- 8 个 LD/ST Unit(与 A100 一致)
- 4 个 SFU(与 A100 一致)
引入了线程块簇,簇是一组保证可以并发调度的线程块,支持跨多个 SM 的线程进行高效协作和数据共享。簇还可以更高效地协同驱动Tensor 内存加速器和 Tensor Core 等异步单元。在物理层次上对应的是GPC,可以直接访问同簇内其他SM的共享内存而不用经过显存中转。
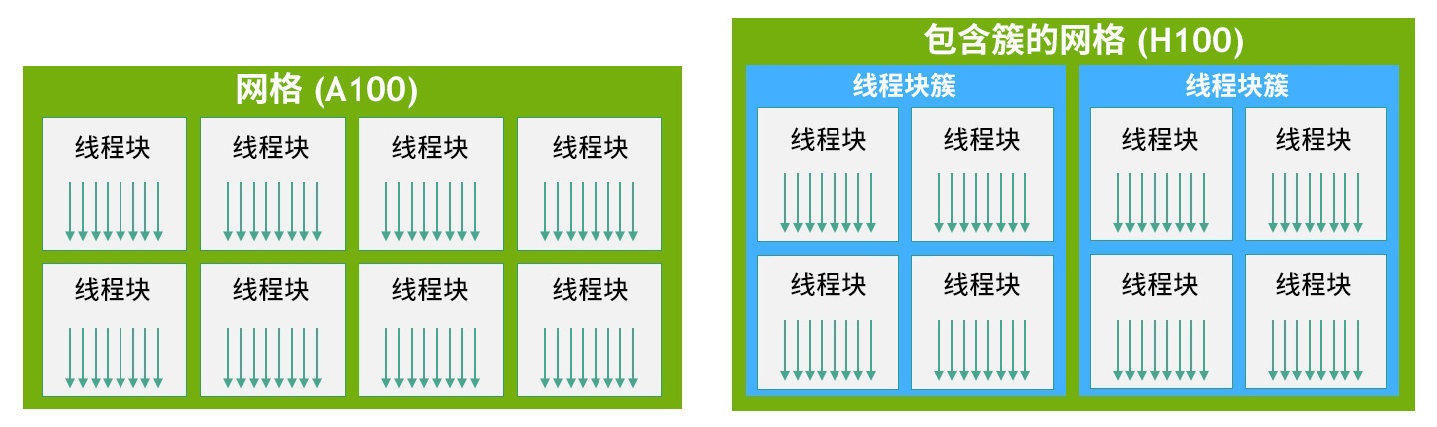

2.3 TensorCore
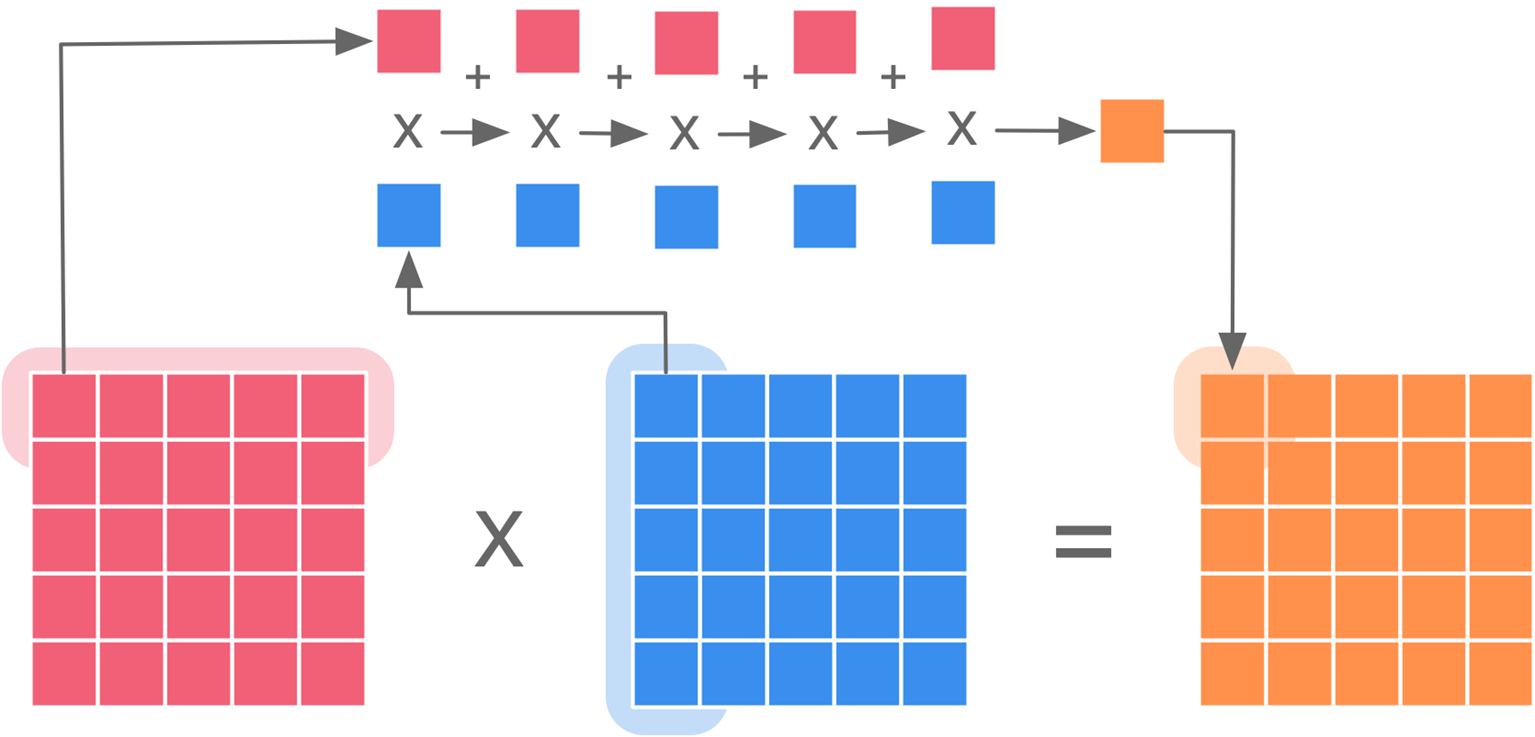
矩阵乘法在进行行列相乘时需要逐元素的相乘累加。这个过程可以使用乘积累加指令FMA(Fused Multiply–accumulate operation)完成。
所谓的FMA指令就是:$a=a+(b\times c)$下图示例需要$5\times 5\times 5$次FMA 完成。
每个 Tensor Core 每周期能执行 $4\times4\times4$ GEMM,64 个 FMA。执行运算 D=AB+C,其中A、B、C 和 D是$4\times4$ 矩阵。矩阵乘法输入 A 和 B 是 FP16 矩阵,而累加矩阵 C 和 D 可以是 FP16或 FP32 矩阵。

Tensor Core执行融合乘法加法,其中两个$4\times4$FP16矩阵相乘,然后将结果添加到$4\times4$ FP16或FP32矩阵中,最终输出新的$4\times4$ FP16或FP32矩阵。
 每个 Tensor Core 每个时钟执行 64 个 FP32 FMA 混合精度运算,SM中8个 Tensor Core,每个时钟周期内总共执行 512 个浮点运算。
每个 Tensor Core 每个时钟执行 64 个 FP32 FMA 混合精度运算,SM中8个 Tensor Core,每个时钟周期内总共执行 512 个浮点运算。
因此在 AI 应用中, Volta V100 GPU的吞吐量与Pascal P100 GPU相比,每个 SM 的 AI 吞吐量增加了 8 倍,总共增加了12倍。

2.4 NVlink
NVLink:英伟达(NVIDIA)开发并推出的一种总线及其通信协议。NVLink采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器(GPU)之间的相互连接。
NVSwitch:是一种高速互连技术,同时作为一块独立的 NVLink 芯片,其提供了高达18路 NVLink 的接口,可以在多个 GPU 之间实现高速数据传输。
NCCL / HCCL: GPU/NPU 通信优化库,支持集中式通信。
资料来源
[1] chenzomi12/DeepLearningSystem: Deep Learning System core principles introduction. (github.com)
[2]TransformAndLighting.pdf (nvidia.com)
[3] 深入GPU硬件架构及运行机制 - 0向往0 - 博客园 (cnblogs.com)
[4]NVIDIA GPU性能优化基础 - 知乎 (zhihu.com)
[6] Life of a triangle - NVIDIA's logical pipeline | NVIDIA Developer
[8]NVIDIA GPU 架构演进 | Chenfan Blog (jcf94.com)